 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ. Zhao
Tensor Networks for Dimensionality Reduction and Large-Scale Optimizations. Part 2 Applications and Future Perspectives
Aug 30, 2017
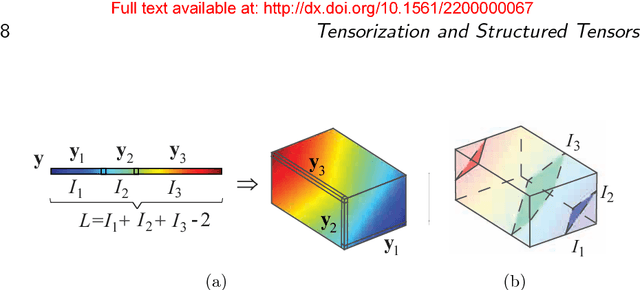

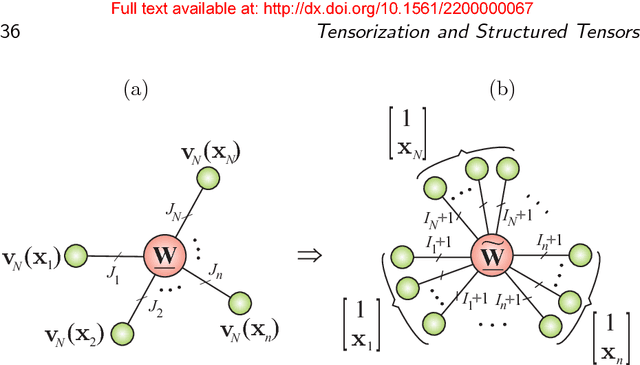
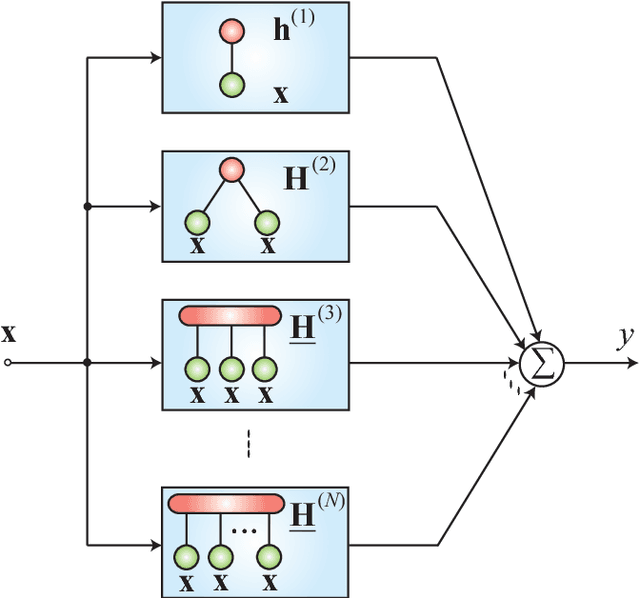
Part 2 of this monograph builds on the introduction to tensor networks and their operations presented in Part 1. It focuses on tensor network models for super-compressed higher-order representation of data/parameters and related cost functions, while providing an outline of their applications in machine learning and data analytics. A particular emphasis is on the tensor train (TT) and Hierarchical Tucker (HT) decompositions, and their physically meaningful interpretations which reflect the scalability of the tensor network approach. Through a graphical approach, we also elucidate how, by virtue of the underlying low-rank tensor approximations and sophisticated contractions of core tensors, tensor networks have the ability to perform distributed computations on otherwise prohibitively large volumes of data/parameters, thereby alleviating or even eliminating the curse of dimensionality. The usefulness of this concept is illustrated over a number of applied areas, including generalized regression and classification (support tensor machines, canonical correlation analysis, higher order partial least squares), generalized eigenvalue decomposition, Riemannian optimization, and in the optimization of deep neural networks. Part 1 and Part 2 of this work can be used either as stand-alone separate texts, or indeed as a conjoint comprehensive review of the exciting field of low-rank tensor networks and tensor decompositions.
* 232 pages
Using Qualitative Hypotheses to Identify Inaccurate Data
Aug 01, 1995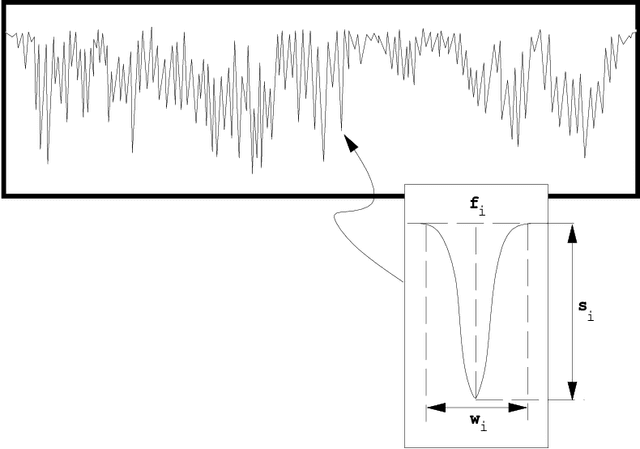
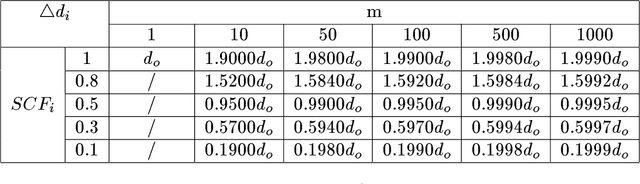
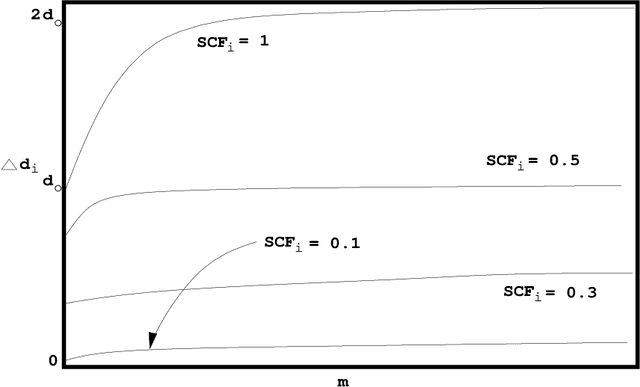
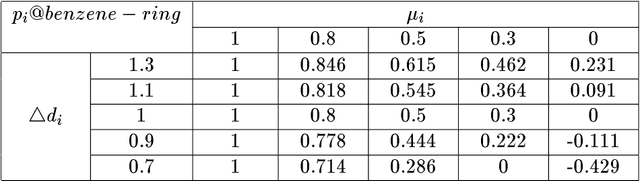
Identifying inaccurate data has long been regarded as a significant and difficult problem in AI. In this paper, we present a new method for identifying inaccurate data on the basis of qualitative correlations among related data. First, we introduce the definitions of related data and qualitative correlations among related data. Then we put forward a new concept called support coefficient function (SCF). SCF can be used to extract, represent, and calculate qualitative correlations among related data within a dataset. We propose an approach to determining dynamic shift intervals of inaccurate data, and an approach to calculating possibility of identifying inaccurate data, respectively. Both of the approaches are based on SCF. Finally we present an algorithm for identifying inaccurate data by using qualitative correlations among related data as confirmatory or disconfirmatory evidence. We have developed a practical system for interpreting infrared spectra by applying the method, and have fully tested the system against several hundred real spectra. The experimental results show that the method is significantly better than the conventional methods used in many similar systems.
* See http://www.jair.org/ for any accompanying files